L'architettura dei sistemi: strato applicativo e gestione dati
tratto dalla rubrica "Informatica" della rivista web e cartacea MyInformando.it
di Armando Pagliara, (aggiornato il 23/01/2021)
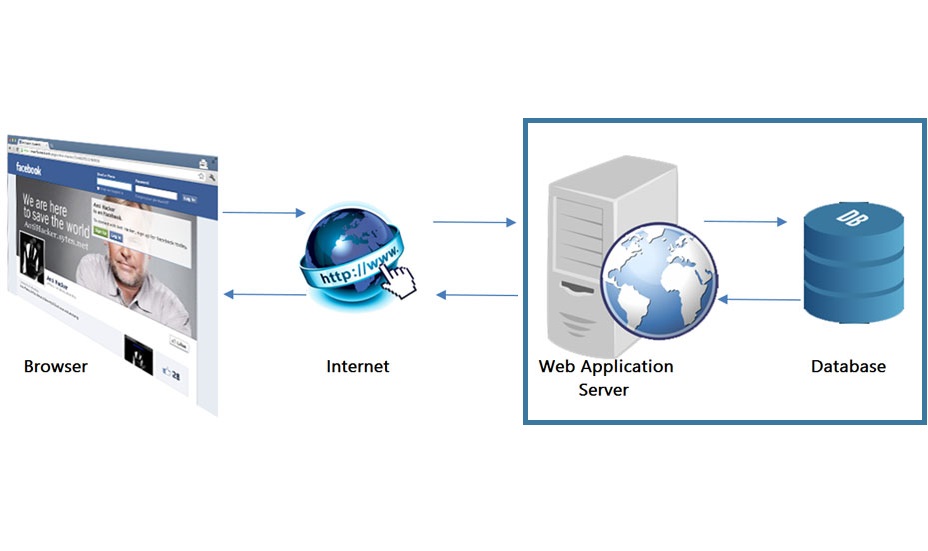
L’architettura software (software architecture) è l'organizzazione di un sistema, definita dai suoi componenti e dalle relazioni tra di essi. Essa si divide in base ai componenti di cui è composto un sistema informatico, mentre l’utente, in genere, interagisce solo con un’interfaccia grafica (U.I.: user interface), dietro la quale diversi strati applicativi (layer) interagiscono tra essi per restituirei i risultati richiesti (output) interrogando un sistema che memorizza le informazioni.
In questo (probabilmente ultimo) articolo sull’architettura dei sistemi ci focalizziamo sulle due parti più nascoste, quelle cioè che si trovano dietro l’interfaccia grafica, che vengono usate dagli strati superiori per leggere, scrivere ed elaborare le informazioni: lo strato applicativo (application layer) e la base di dati (database), rispettivamente l’insieme delle strutture di controllo ed elaborazione ed il sistema per la memorizzazione ed interrogazione delle informazioni.
Utilizzando come esempio sempre il nostro noto social network Facebook (di cui, ribadisco, non conosco la struttura ma generalmente rispecchia uno stereotipo comune noto come “architettura web”), cerchiamo di capire come sono fatti e a cosa servono lo strato applicativo e la base di dati. Per capirlo, simuliamo l’azione di autenticazione (log-in).
Per accedere al social network bisogna, per prima cosa, digitare email (o numero di telefono) e password. Al “clic” del pulsante otteniamo una “risposta”, che può essere di due tipi: le credenziali sono giuste, quindi possiamo visualizzare la nostra pagina… oppure abbiamo sbagliato qualcosa. Ma cosa accade alla pressione di quel pulsante?
La pagina web che l’utente vede in realtà non è quella presente sul server originale, ma è generata dallo strato applicativo ed è scritta in un linguaggio di programmazione lato server (server side). Per fare un esempio pratico, è come paragonare lo scontrino fiscale (pagina) che ci emette la cassa al supermercato come il prodotto del lavoro della cassiera (l’inserimento dei dati del conto). Nel caso di Facebook, il linguaggio di base è il PHP (acronimo ricorsivo di "PHP: Hypertext Preprocessor"), che ci permette di compiere elaborazioni, leggere e scrivere nella base di dati e assemblare i dati per la presentazione all’utente.
Ma una volta premuto il pulsante ed inviate le informazioni da controllare, dove sono memorizzate email e password? Ovviamente nella base di dati. Rispetto alla “posizione” dell’utente, questo è componente più lontano e praticamente irraggiungibile manualmente partendo dall’interfaccia grafica (UI).
Una base di dati è una raccolta di informazioni strutturata, generalmente, a tabelle (base di dati relazionale), che rappresentano concetti semplici. Ad esempio, una tabella di nome UTENTE conterrà le informazioni di login, come username e password, i nostri dati di base come nome, cognome e data di nascita, l’indirizzo di posta ed il numero di telefono.
Poi, probabilmente, esisterà un’altra tabella (in realtà la struttura dovrebbe essere molto più complessa) che chiameremo PUBBLICAZIONE, che conterrà le nostre pubblicazioni, contenente testo, immagine, “mi piace”, data e ora di pubblicazione, collegamento alla bacheca su cui è pubblicata (la nostra o quella di qualche amico, o gruppo), eventuali allegati come file o link a siti web e una lista di commenti.
Attenzione al tipo di informazione però: solo i dati cosiddetti “primitivi” possono essere memorizzati in una tabella, mentre le liste di commenti o di “like” vanno inseriti in un’altra tabella (ad esempio COMMENTO) che verrà poi collegata a quella di base mediante il concetto di identificativo, tecnicamente dettl chiave. La chiave rappresenta le informazioni di quella riga in modo univoco, un po’ come la nostra email all’interno di Facebook: nessun altro potrà avere la stessa email per l’accesso. A questo punto passiamo ad un esempio pratico.
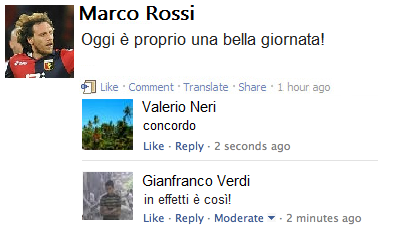
Mettiamo il caso che l’utente Marco Rossi stia pubblicando sulla sua bacheca questo messaggio: “Oggi è proprio una bella giornata!”. A questo punto i suoi amici Valerio Neri e Gianfranco Verdi gli aggiungeranno un commento come “concordo” e “in effetti è così!”: ogni tabella deve avere un identificativo per individuare quell’insieme di informazioni.
Utilizziamo l’email come identificativo degli utenti (ad esempio marco.rossi000@gmail.com per Marco Rossi), un nome per identificare la bacheca di un utente (mr00_bacheca01 sarà la sua bacheca), uno per il messaggio inserito (usando nome utente, i caratteri “msg” ed un numero) e uno per i commenti (creato sempre con nome utente, i caratteri “cmt” e un numero).
Proviamo quindi a generare un esempio di dati per UTENTE, PUBBLICAZIONE e COMMENTO.
La tabella UTENTE conterrà sicuramente i tre utenti in questione, in una struttura simile alla seguente:

Dopo l’inserimento del messaggio in bachera, la tabella PUBBLICAZIONE conterrà una riga come la seguente:

Dopo l’inserimento dei commenti, la tabella COMMENTO conterrà:

In che modo è possibile aggregare le informazioni e farle uscire in pagina? Sarà lo strato applicativo a prendere questi messaggi e a scriverli nella base di dati, così come li leggerà e, a partire dalla richiesta dell’utente, costruirà la lista di messaggi utilizzando gli identificativi: marco.rossi000@gmail.com è agganciato alla bacheca mr00_bacheca01, al cui interno si trova il messaggio marco.rossi000_msg101 e i suoi commenti, agganciati al messaggio, denominati valerioner0002_cmt01 e gianf.verdox_cmt02.
Semplice, no?